Whisper 논문인 ' Robust Speech Recognition via Large-Scale Weak Supervision'와 해당 git repo를 기반으로 공부하여 정리하였습니다. 글의 순서는 다음과 같습니다.
whisper 개요
모델 작동 방식
모델 성능
모델 관련 이슈
1. whisper 개요
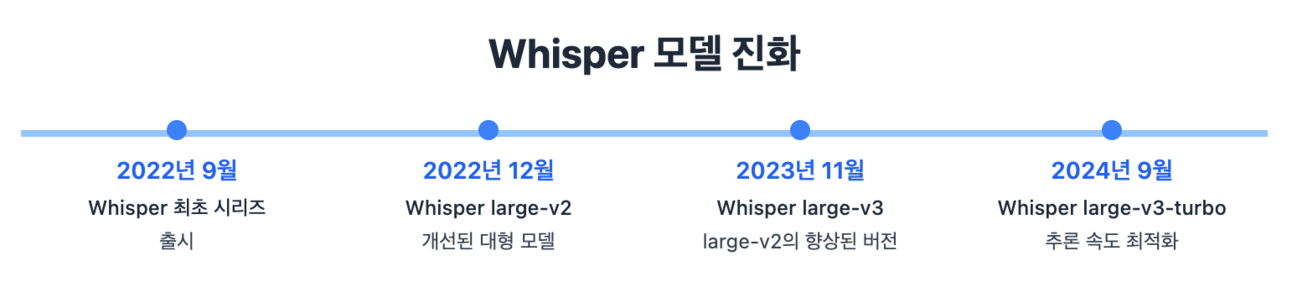
OpenAI Whisper는 OpenAI가 2022년에 공개한 자동 음성 인식(ASR) 모델로, 약 68만 시간 분량의 대규모 다국어 음성-텍스트 데이터를 학습하여 개발되었다. 논문 “Robust Speech Recognition via Large-Scale Weak Supervision”에서 소개된 이 모델은 이름 그대로 대규모의 약한 감독(Weak Supervision) 데이터를 통해 학습되었다. 다시 말해 약간의 노이즈가 껴있더라도 저렴하게 대규모 데이터를 수집하여 학습한 모델이라는 말이다. 학습 데이터의 대부분은 공개된 웹 기반 음성 데이터셋에서 수집한 것으로, 전문적으로 라벨링 없이 전처리 과정을 최소화한 영상 자막 데이터들을 활용했다고 한다. 이러한 약한 감독(Weak Supervision) 접근 방식은 기존의 고품질 라벨 데이터에 의존하던 ASR 시스템과 달리 훨씬 더 확장성이 좋고, 다양한 환경에 노출시킴으로써 모델을 더욱 robust하게 하는 효과를 발생시킨다.
24년 9월까지도 large-v3-turbo 모델을 추가 공개하는 등 지속적으로 업데이트가 이어지고 있다. 오픈 소스인데다가 한국어까지 지원되는 모델로, 극히 드문 한국어 stt 모델 선택지 중에서도 높은 정확도를 보여주는 활용도 높은 모델이라는 생각이 든다.
2. 모델 작동 방식
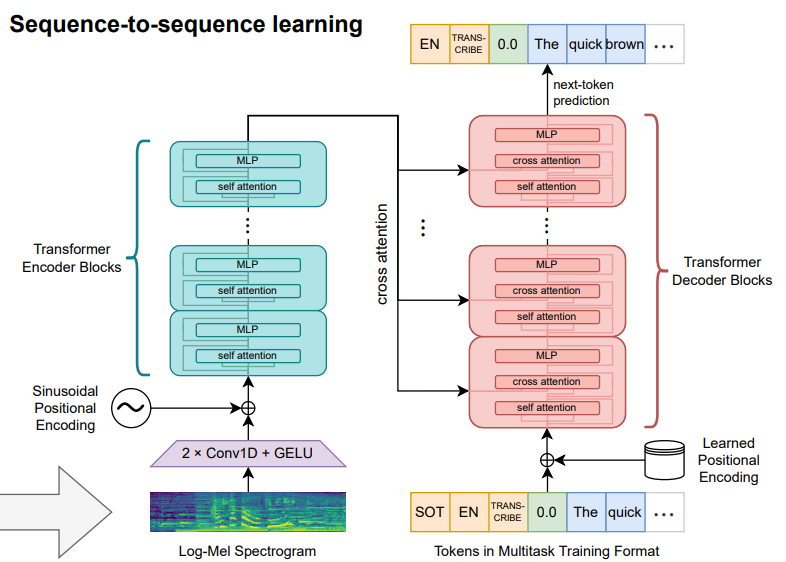
whisper 모델도 transformer의 encoder-decoder 구조를 사용하고 있다. 자연어 처리에서 사용하는 모델의 구조와 거의 유사하지만 오디오 데이터가 입력된다는 점에서 몇가지 차이가 존재한다.
2.1 Log-Mel Spectrogram
우선 일반적인 mp3, wav 등의 음성파일을 모델이 인식할 수 있는 형태로 변환해줘야 한다. 그것이 바로 mel-spectrogram 형태이다. 이건 어떻게 만들어지는 것일까!
오디오 샘플링 소리란 사실 공기의 압력 변화이다. 따라서 소리는 끊임없이 변하는 파형으로 이루어져 있으며, 이걸 디지털로 바꾸기 위해 아주 빠른 속도로 샘플링한다. 샘플링 레이트가 높을수록 더 정확하고 고품질의 오디오를 얻을 수 있다. whisper에서는 16,000Hz로 오디오 샘플링을 한다. (1초에 16,000번 샘플링) -> 이렇게 해서 만들어진 것이 바로 오디오 파형 (waveform)이다. 출처 : Understanding the Mel Spectrogram
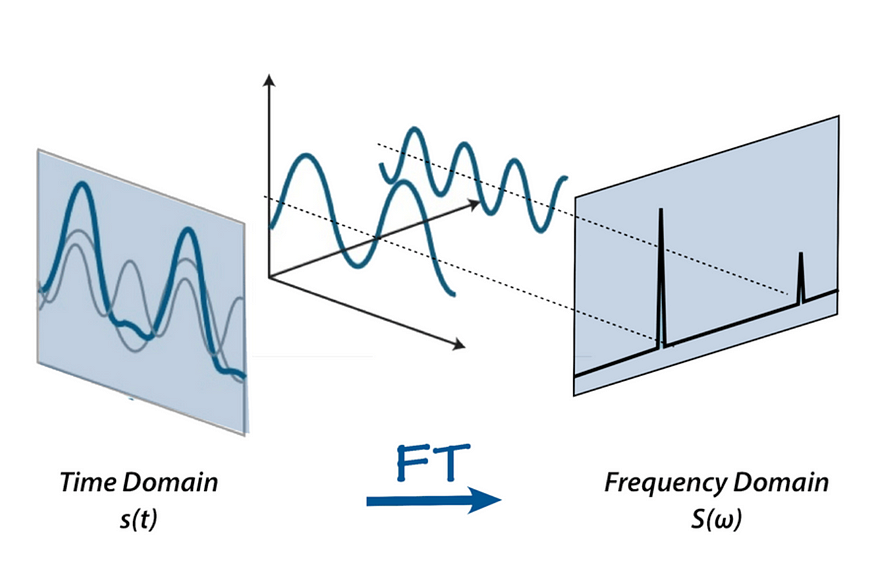
Spectrogram 변환 하지만 위의 파형을 보고서는 이건 어떤 음인지, 어떤 소리인지 직관적으로 알 수 없다. 그래서 Fourier Transform으로 주파수 분석을 한다. 푸리에 변환은 소리를 구성하는 주파수와 세기 (amplitude)로 변환해준다. -> 오디오가 어떤 '음들'로 이루어졌는지 분석할 수 있게 해준다. 하지만, 우리는 시간에 따라 변화는 주파수의 세기가 궁금한 것인데, 푸리에 변환은 오디오 파형을 각 주파수별 세기로만 표현해준다.출처 : Understanding the Mel Spectrogram
따라서 시간에 따른 변화를 표현하기 위해, 짧게 짧게 끊어서 각각 FT를 수행해야 한다. -> 이걸 Short-Time Fourier Transform (STFT) 라고 한다. 아래의 이미지처럼 슬라이딩 윈도우 방식으로 오디오를 ms 단위로 짧게 끊고, 겹치면서 분할 후, 푸리에 변환을 한다. whisper에서는 25ms 단위로 오디오를 자르고, 10ms 단위로 겹치면서 슬라이딩 윈도우 방식을 적용하였다. 출처 : Understanding the Mel Spectrogram 이렇게 하면 시간에 따라 변화하는 주파수의 세기를 히트맵 형식으로 구할 수 있다. 이것이 바로 spectrogram이다. 출처 : Understanding the Mel Spectrogram
Mel-spectrogram 변환 일반적으로 사람은 500Hz와 1000Hz의 차이는 잘 구분하지만, 10,000Hz와 10,500Hz의 차이는 잘 구분하지 못한다. 이처럼 저주파에는 민감하지만 고주파에는 둔감하게 반응한다. 즉, 인간의 귀는 주파수를 선형적으로 인식하지 못한다. 그래서 사람이 느끼는 주파수 간격을 반영하기 위해 등장한 것이 mel scale이다. 그리고 spectrogram의 y축을 mel 단위로 바꾼 것이 mel-spectrogram이다. 출처 : Understanding the Mel Spectrogram
log 변환 모델의 학습면에서 유리하기 때문에 log 변환을 많이 하는 편이라고 한다.
2.2 Encoder
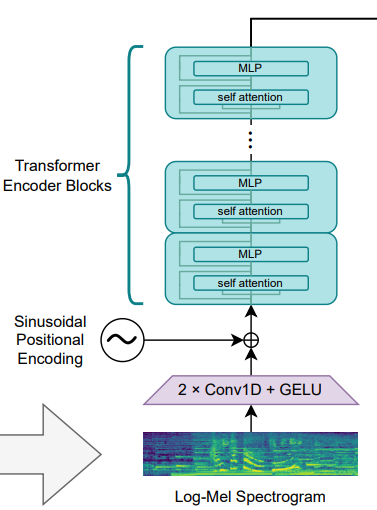
log mel-spectrogram 데이터는 시간 X 주파수 형태의 2D 텐서로 표현할 수 있다. 따라서 이미지와 같은 방식으로 처리할 수 있다. whisper에서는 conv layer를 2번 쌓아서 음성 데이터를 저수준 표현으로 변환해준다. 이 후는 일반적인 transformer의 인코더와 동일하게 시간 순서를 표현할 수 있는 positional encoding을 더해준 후, 입력 데이터를 잘 표현할 수 있는 벡터로 인코딩해준다.
2.3 Decoder
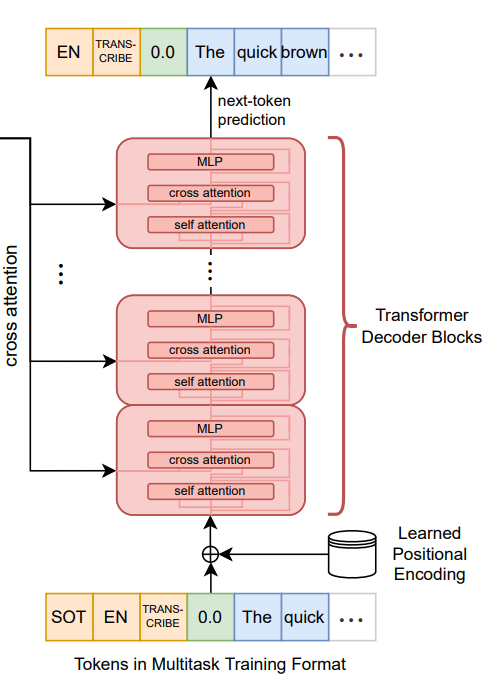
encoder의 인코딩 값과 cross attention을 수행하며 다음에 나올 토큰을 예측하는 방식으로 음성 전사(transcription)를 수행하게 된다.
2.4 Multi-task
whisper의 가장 큰 특징 중 하나였던 멀티 태스킹 기능. 이것은 어떻게 수행되는 것일까?
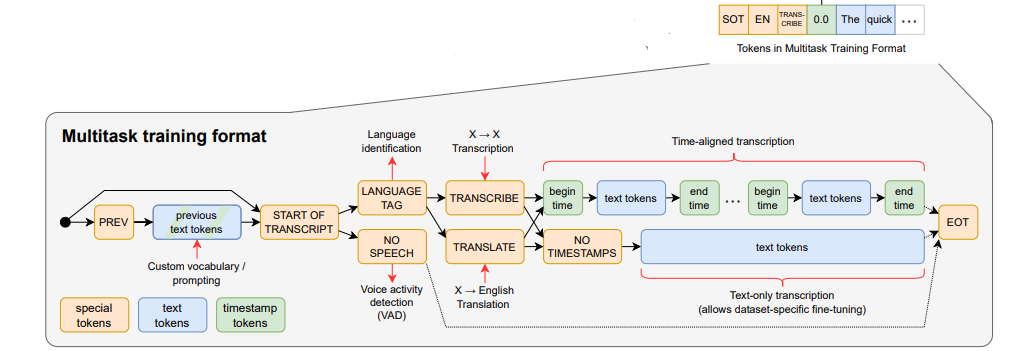
전사, 번역, 음성 감지 등 여러 기능을 한번에 수행하는 만큼 어떤 기능을 수행할 것인지 모델에게 명확하게 전달해주는 것이 중요하다. 이를 위해 whisper는 토큰 기반 task 지시어를 사용한다.
다음의 토큰들을 디코더의 input으로 넣어줌으로써 task를 인식하도로고 하였다.
Start of transcript <|startoftranscript|> 토큰이 입력되면 음성 전사를 시작하게 된다.
Language Tag 현재 입력된 음성 데이터의 언어를 식별한다. 음성을 전사하기 전에 언어 식별을 위한 latency가 발생하게 되므로, 입력되는 음성의 언어를 알고 있는 경우에는 language를 지정해줄 것을 권장하고 있다.
No speech 음성 데이터에서 실제로 사람이 말하는 경우와, 기타 잡음을 판별하기 위해 <|nospeech|> 토큰의 확률을 계산하게 된다. 이 확률 값이 특정 임계치를 넘게 되면 음성이 입력되지 않은 것으로 판단하여 음성 전사를 수행하지 않는다.
Transcribe/Translate whisper는 기본적으로 전사 뿐만 아니라 영어 번역까지 함께 제공하고 있으므로, 이 중 어떤 task를 수행할 것인지지 <|transcribe|> 또는 <|translate|> 토큰으로 표현해준다.
Timestamps 음성을 텍스트로 변환할 때 각 토큰들의 타임스탬프를 함께 예측할 수도 있다. 영상 자막 생성할 때 주로 싱크를 맞추기 위해 사용된다. <|notimestamps|> 토큰이 입력되면, 타임스탬프 예측은 생략하고 텍스트 토큰만 예측하게 된다. 반면에 해당 토큰이 입력되지 않으면, 각 토큰/세그먼트 별로 타임스탬프를 예측하게 되는데, 어떻게 예측할까... 생각보다 단순한 방식을 적용하였다. time을 20ms 단위로 토큰으로 만들어버리고, 이 타임 토큰을 텍스트 토큰 전후로 함께 예측하도록 하였다. 즉, <|0.00|>, <|0.02|>, ..., <|29.98|> 와 같은 수천개의 타임 토큰들이 단어처럼 예측된다. ex. <|0.00|> Hello, how are you? <|1.80|>
End of transcript <|endoftranscript|> 토큰이 출력되면 음성 전사가 마무리된다.
3. 모델 성능
3.1 영어 인식
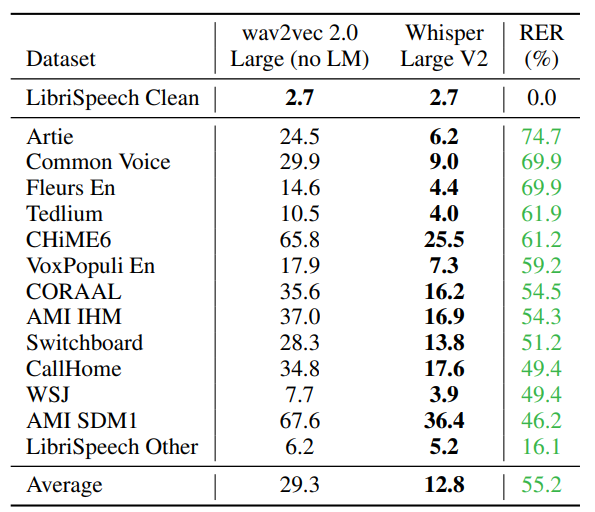
논문이 발표될 당시 비교대상이 되던 wav2vec 모델과 large-v2을 LibriSpeech Clean 벤치마크로 비교했을 때는 거의 비슷한 성능을 보인다. 하지만, 그 외의 다양한 데이터셋을 통해 평가해본 결과, whisper 모델이 훨씬 좋은 성능을 보였다. 이를 통해 whisper의 일반화 능력이 뛰어남을 엿볼 수 있다.
3.2 다국어 인식
다음은 turbo 모델과 함께 git에 공개된 모델 성능 그래프이다. large-v2 > large-v3 > turbo 모델 순으로 출시되었다. large-v3는 기존 large-v2 모델에서 토큰/데이터를 추가 학습함으로써 전반적으로 WER이 낮아진 것을 확인할 수 있다. 이 후 공개된 turbo모델은 large-v3에서 디코딩 레이어를 32개 → 4개로 대폭 축소함으로써 추론 속도를 최적화한 모델이다. 이를 통해 훨씬 빠른 추론 속도와 large-v3와 비교했을 때 크게 뒤처지지 않는 성능을 보인다.
* 기울임체로 써진 국가들은 WER 대신 CER로 계산되었다.
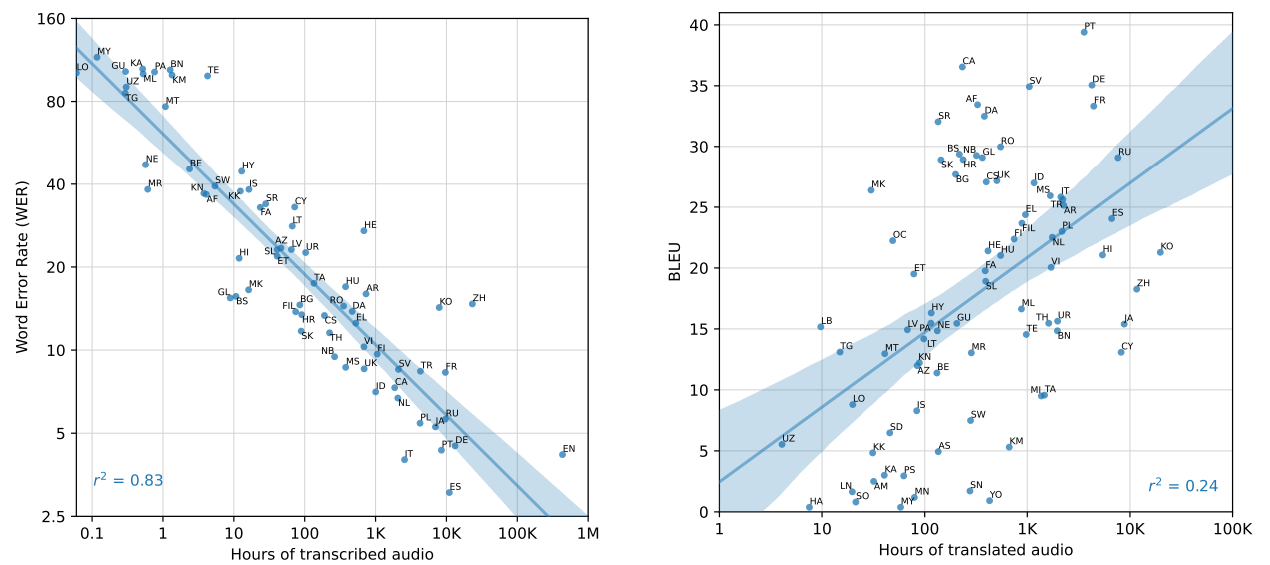
다만, 위 그래프에서도 확인할 수 있듯이, 각 언어별로 성능 차이가 큰 편이다. 일반적으로 학습에 사용된 데이터가 적거나 (저자원), 독특한 문자 체계를 갖는 언어들에서 낮은 성능이 나타났다. 아래 그래프는 학습된 오디오 데이터 시간에 따른 성능을 나타낸 그림이다. 학습 데이터가 많을수록 낮은 오류율을 보인다. 이 중에서도 평균적인 언어 성능 경향성(trend)에서 크게 벗어난 outlier 언어들이 존재하는데, 다음의 언어들이 그렇다.
Hebrew (히브리어)
Telugu (텔루구어, 인도 남부 드라비다계 언어)
Chinese (중국어)
Korean (한국어)
아쉽게도 한국어가 그렇다.. Indo-European 계의 언어 체계와 거리가 먼 언어들이다. 한국어는 다른 언어들과 비교했을 때도 학습 데이터 수가 굉장히 많은 편에 속한다. 그에 비해 성능은 약간 아쉬운 편이다.
3.3 음성 번역
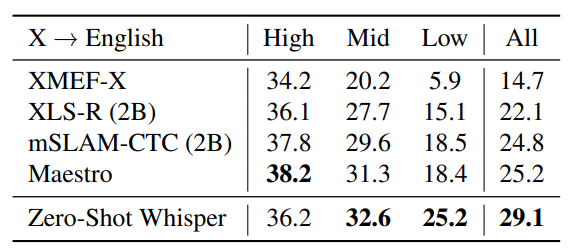
CoVoST2 벤치마크에서 whisper 모델이 새로운 SoTA 기록을 달성했다. Whisper는 사전 학습에서 무려 68,000시간 분량의 X→en 번역 데이터를 사용함으로써 기존의 모델들의 성능을 능가할 수 있었다.( 대규모 학습을 통해 모델의 성능을 최대한으로 끌어올리고자 했던 openai의 초기 목표를 잘 달성한 것으로 보인다.
특히 저자원 언어 그룹에서 성능 향상이 두드러진다. 반면, 고자원 언어 그룹에서는 mSLAM이나 Maestro보다 특별한 우위를 보이진 않았다.
4. 모델 관련 이슈
4.1 할루시네이션
Whisper는 오디오에 없던 단어를 마치 있었다는 듯이 생성하는 현상이 발생한다. (discussion)
Whisper 학습에 사용된 데이터들은 대부분 노이즈가 많고, 완전히 정제되어 있지 않기 때문에 “오디오 ↔ 텍스트”가 일치하지 않는 경우도 포함되어 있다. 이로 인해 모델이 실제 오디오와 다르게 그럴듯한 텍스트를 생성할 가능성이 높다.
Whisper는 단순한 음성-텍스트 대응 모델이 아니라, Transformer 기반 Seq2Seq 구조로 언어 모델적인 특성도 가지고 있다. 즉, 말이 되게 텍스트를 생성하려는 경향이 있다. 오디오 정보가 불완전하거나 불명확할 때는 언어적 추론에 더 의존하게 되어, 실제로 들리지 않은 내용을 추측해서 생성하는 일이 발생한다.
할루시네이션 방지용으로 hallucination_silence_threshold 라는 모델 인자를 제공한다. 이는 공백(silence)발생 시 할루시네이션이 자주 발생하게 된다는 점에서, 할루시네이션 감지 시 threshold 이상의 silence 부분은 제외하고 다시 모델에 입력하여 전사하도록 한다.
4.2 반복적인 텍스트 생성
Whisper는 때때로 같은 단어 또는 구절을 반복해서 생성하는 오류를 보인다. (ex. “감사합니다 감사합니다 감사합니다…”) (discussion)
Transformer 기반의 Seq2Seq 모델 구조는 출력을 순차적으로 생성하는데, 이전 출력을 다음 출력에 참고하는 오토리그레시브(autoregressive) 특성 때문에, 반복이 쉽게 유도될 수 있다.
Beam search, temperature 설정 조절을 통해 반복을 줄일 수는 있지만, 근본적인 해결책은 아니다.
4.3 타임스탬프 정확도 문제
Whisper는 음성-텍스트 전사에서 뛰어난 성능을 보이지만, 단어 단위 혹은 프레임 수준의 타임스탬프 예측 정확도는 떨어진다. (discussion)
Transformer decoder 자체가 토큰 단위 예측만 하므로, 무엇을 말했는지에 초점을 맞추고, 언제 말했는지는 간접적인 추론 수준이다.
학습 시 Cross-Entropy Loss를 사용함으로써 오직 정답 토큰(텍스트)을 얼마나 잘 예측했는지만 따지고, 타임스탬프는 학습 손실에 포함되지 않는다. 이 때문에 모델은 정확한 단어를 생성하는 데 집중하고, 정확한 시점에 그 단어가 발생했는가는 신경 쓰지 않는다.
whisper 모델은 스트리밍 처리에 최적화되어 있는 모델이 아니다. (discussion)
한 번에 30초 길이의 오디오를 일괄 처리하기 때문에, 실시간으로 입력되는 음성을 처리하지는 못한다. 따라서 짧은 지연 시간(latency)이 중요한 실시간 응용(예: 회의 실시간 자막, 전화 통역 등)에서는 제한적이다.
git에서 몇가지 대책들을 제시해주기는 한다. 음성을 1-2초 단위로 짧게 잘라서 모델에 입력함으로써 스트리밍과 유사한 방식으로 작동하도록 할 수 있다고 한다. 물론 기존에 30초 단위로 긴 맥락을 유지하여 학습되던 방식과 달리 짧게 끊긴 음성이 들어옴으로써 성능이 저하되는 것은 불가피하다. 이를 좀더 보완해서 whisper_streaming이라는 구현체도 공개되어 있다.